Machine learning can feel like a maze of algorithms and techniques, but sometimes, the most effective methods are actually very simple at heart. One of these methods is called bagging. Short for Bootstrap Aggregating, bagging is a smart way to improve the accuracy of machine learning models by combining several versions of a model together. This might sound a bit technical at first, but once you understand how it works, you'll see why it's such a reliable tool to have.
Why Bagging Works So Well
One of the largest problems in machine learning is overfitting. This occurs when a model performs well on the training data but does poorly when given new, unseen data. It's like preparing for an exam by memorizing old questions rather than learning the material. When the exam becomes different, you're out of luck.
Bagging avoids this issue by building numerous copies of the same model, each of which is trained on a slightly different cut of the data. It's similar to having 50 friends all take a practice test and then putting all their answers together to create your final answer key. The thought is, sure, one model may make errors, but the collective is better at getting it right.
Each model learns something a little bit different because each one views different data. When all of these models "vote" in concert, the final result is typically much more accurate than depending on a single one.
How Bagging Actually Works
Let’s break it down into simple steps:
Sampling the Data
Bagging begins by sampling the original set at random. There's a catch, though: each sample is sampled with replacement. This implies that one data point may occur more than once in a sample, whereas others may not occur at all. Imagine drawing a name from a hat, recording it, and then returning the name to the hat before drawing again.

This small detail—sampling with replacement—is what introduces just the right amount of randomness. If we trained every model on the exact same data, they would all make the same mistakes. However, by training them on slightly different versions, each model picks up different patterns. The combined wisdom from all these models makes the final prediction stronger and more reliable.
Training Multiple Models
A separate model is trained for every sample created. Usually, these are the same type of model, like decision trees, because they are quick to train and prone to overfitting—which bagging is especially good at fixing.
Each model works independently, without any influence from the others. This independence is important. If the models depended on each other while learning, the method would start looking more like boosting, not bagging. By keeping the models separate, bagging ensures that the final result balances out the random mistakes that individual models might make.
Combining Predictions
Once all models are trained, their results are combined. If it’s a classification task, they vote, and the most common answer wins. If it’s a regression task, the results are averaged.
A bonus trick when using bagging is something called Out-Of-Bag (OOB) error estimation. Since not every data point ends up in every sample, the data points left out (the "out-of-bag" points) can be used to estimate how well the model performs without needing a separate validation set. It's like getting a free performance check while you train.
This simple idea of "train multiple models and combine" might seem almost too easy, but it works incredibly well, especially when individual models are prone to making errors in slightly different ways.
Popular Models That Use Bagging
Bagging isn't just a cool idea—it's the engine behind some of the most trusted machine-learning models today.
Bagged Decision Trees
Decision trees are very sensitive to the training data. They can swing wildly with just a small change in the data. But when you use bagging, these swings cancel each other out, and you end up with a more stable and accurate prediction.
Random Forest
Random Forest takes bagging one step further. Not only does it create random samples of the data, but it also selects a random subset of features for each tree. This extra randomness makes the final model even better at avoiding overfitting. It's no wonder Random Forest is often one of the first models people try when tackling a new machine-learning problem.
Bagged SVMs and Neural Networks
Though decision trees are the most common, you can technically use bagging with any model, including Support Vector Machines (SVMs) or even simple neural networks. However, since these models can take a lot longer to train, they are less common.
Bagging vs. Boosting: Are They the Same?
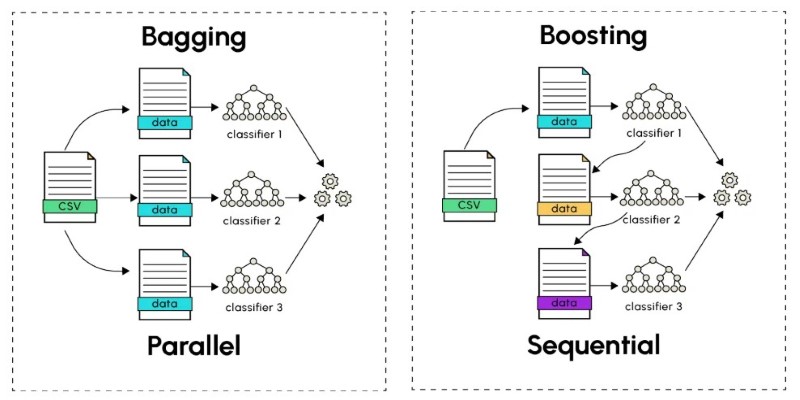
If you've been reading about machine learning, you might have come across another term: boosting. While both methods create multiple models and combine their outputs, the key difference is how they treat the models.
- Bagging creates models independently. Each model is trained on a different random sample without caring how the others did.
- Boosting builds models one after the other. Each new model tries to fix the mistakes made by the previous one.
Bagging is like asking 50 people for their independent opinions on something. Boosting is like having a team where each person is trying to improve on the last person's work.
Wrapping It Up
Bagging is one of those methods that reminds us good ideas don't have to be complicated. By simply training multiple models on random subsets of data and combining their outputs, bagging helps create more accurate, stable predictions. Whether you're working with decision trees, SVMs, or even neural networks, bagging offers a straightforward way to reduce variance and build models you can trust. And if you're curious to see bagging in action, Random Forest is a perfect place to start. It's like bagging a cooler older cousin—with a few extra tricks up its sleeve!











